Data quality with AWS Lambda
How to use AWS Lambda to do data quality checks without increasing data pipelines complexity



Overview
During the data ingestion stage, data engineers should be prepared to anticipate as much as possible that can go wrong and appropriately handle issues caused by poor quality data. Not so rarely, data pipelines are broken by poor quality data. In general, to maintain these data pipelines healthily, data engineers code a lot of data quality checkers
Besides being the right way, data quality checkers increase the complexity of our data pipeline uprising the costs to keep it running. When data comes from several sources in a not-so-rigid scheme, the problem tends to be bigger.
You can find all the codes in my repository: github.com/igorccouto/aws_lambda_data_quality
Scenario
Imagine you need to maintain a basic data pipeline in AWS. It processes several CSV files sent by many users. The size of the files is not so big, but it comes on a regular time basis all day. It's necessary to clean, transform, enrich, and save the data in a proper database every time a new file is uploaded by a user.
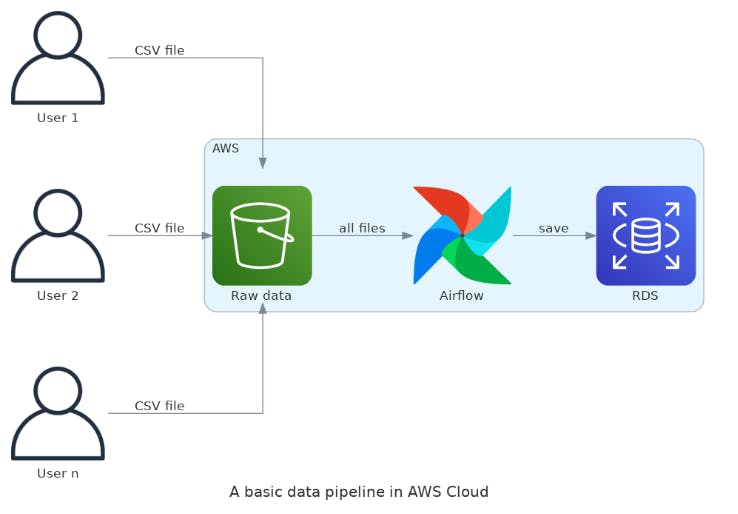
The CSV files are ingested from an S3 bucket, and an MWAA instance (Apache Airflow) contains all the workflow to clean, transform, enrich and save the data in a relational database. Everything it's going great until users send files with...
- missing or wrong-named columns;
- strange file encodings;
- missing values or wrong types;
- anything to mess up.
In fact, several of these issues can be filtered in a primary system. For instance, the users don't have access to the S3 bucket directly. They upload files to a web application responsible to put the CSV files in the bucket. Here is the right place to avoid some bad files.
The above scenario would be the best of both worlds, but a good data engineer doesn't count on it. So, you have to develop code to validate files. Is it possible to place data quality checkers without changing my deployed data pipeline a lot? Or not increasing the complexity? Yes!
AWS Lambda and our data pipeline
AWS Lambda is a compute service from AWS where you don't be bothered to manage servers - serverless. You place your code in Lambda functions and it will run every time it is triggered. Lambda has a lot of integration with other AWS services and with S3 it would not be different.
As AWS Lambda is event-driven, it fits very well with what we need. The idea is to trigger the data quality checker every time the bucket receives a CSV file. Let's rearrange our diagram to explain it better.
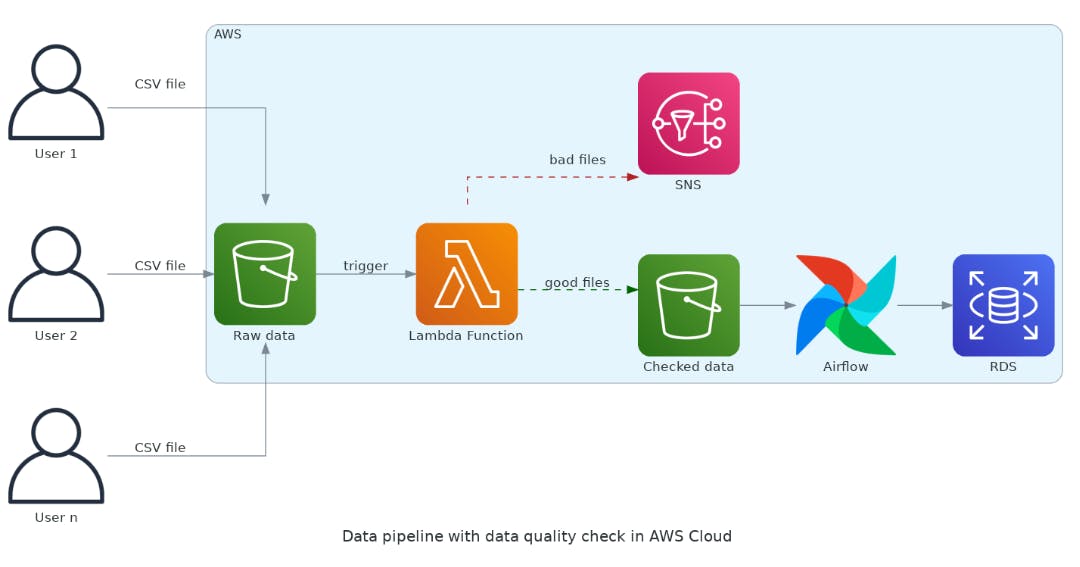
We place a Lambda function between the S3 bucket and the begging of the data pipeline in MWAA. The Lambda function will separate the sheep from the goats. Good files will be placed in a new S3 bucket to flow in the data pipeline. Definitely, you just need to point the beginning of the MWAA workflow to the new bucket. Note the users continue to place CSV files in the same bucket. For them, nothing changed!
Additionally, we redirect bad files to the AWS SNS just to show you can do anything. According to your business rules, you can put bad files on another S3 bucket to posterior treatment, send emails to users, trigger another Lambda function or even do nothing. Just keep in mind this part is not the scope of this article.
Let's get down to work!
To be simple, we will create a new Lambda function to check if the CSV file has a header and if the name of the columns is correct. Yet, the checkers can address all possible problems described in the above scenario.
If you want to use some codes from this article, please install Python 3, boto3, and AWS CLI and configure them on your machine. If you already have a AWS account and chose a region follow the steps below.
Creates a role to execute the Lambda function
An execution role gives your Lambda function permission to upload logs and access other AWS services. Add policies to the execution role to give it access to downstream resources, such as S3 buckets. Let's create a role to set in your Lambda function later. In IAM console:
- Go to Access Management >> Roles. A list of defined roles will be shown to you.
- Click on Create role.
- Select AWS service in the Trusted entity type and Lambda in the Use case.
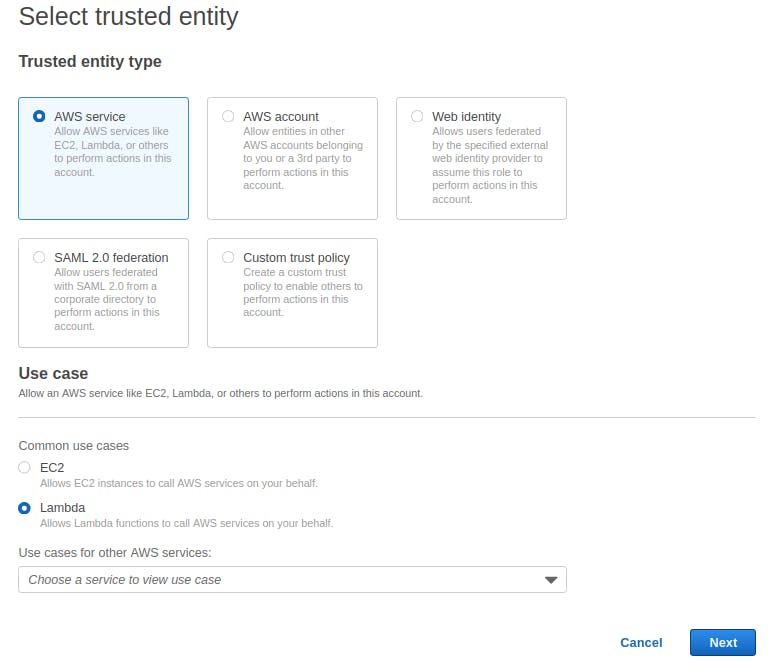
On the next page will be listed the permissions policies. To be simple, just select AmazonS3FullAccess and CloudWatchLogsFullAccess. Advice: Never put permission police like that in production! It's not a good practice. Here we are just setting for learning purposes. Click in Next.
In Role details, give a name to the role, like LambdaAccessS3DataQuality. If everything is ok, click on Create role.
Creates the new bucket to save good data
There are many ways to create an S3 bucket. In the S3 console:
- Go to Buckets >> Create bucket.
- On Create bucket page, choose a name for the bucket and region.
- You can keep all the other options in default.
- Finish in Create bucket.
If you have boto3 and AWS CLI installed on your machine, you can easily create a new bucket with the Python code:
import boto3
def main():
bucket_name = '<NEW_BUCKET_NAME>'
s3_client = boto3.client('s3')
s3_client.create_bucket(Bucket=bucket_name)
response = s3_client.list_buckets()
print('Existing buckets:')
for bucket in response['Buckets']:
print(f' {bucket["Name"]}')
if __name__=='__main__':
main()
Open the AWS S3 console if you want to check it's everything fine.
Creates the Lambda function
Finally, it's time to access the AWS Lambda console to see the dashboard. Here, you can note that I already have a Lambda function deployed as some other information about the service. Feel free to explore.
To create the Lambda function, proceed:
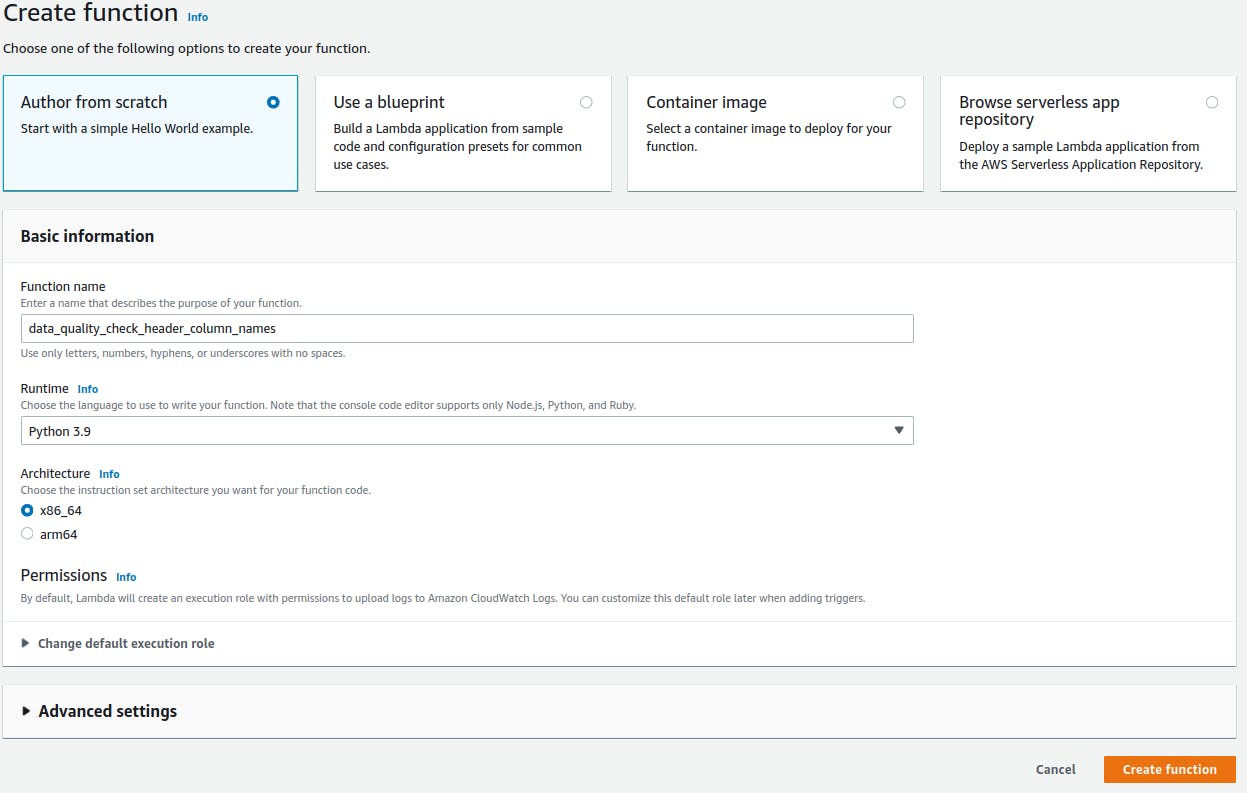
- Click in Create function.
- Select Author from scratch
- Give a name to your function - data_quality_check_header_column_names.
- Select Python 3.9 in Runtime.
In Execution role, select Use an existing role and choose the role created in the previous step.
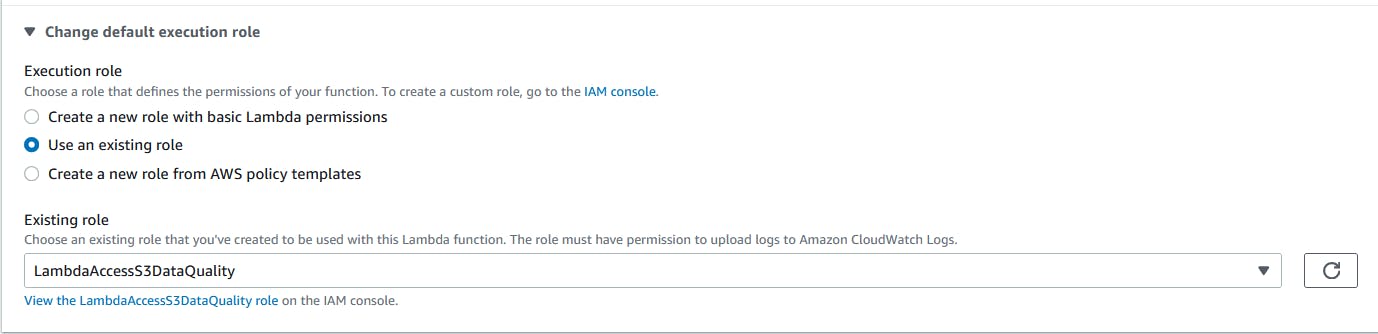
If everything is correct, proceed in Create function again.
After a while, the console will show the Lambda function overview.
Scrolling the page down, you can see an editor with a Python hello-world function inside. By default, when an event triggers the function, the Lambda service calls the lambda_handler to handle the event. We can change this entry point, but it's enough for now.
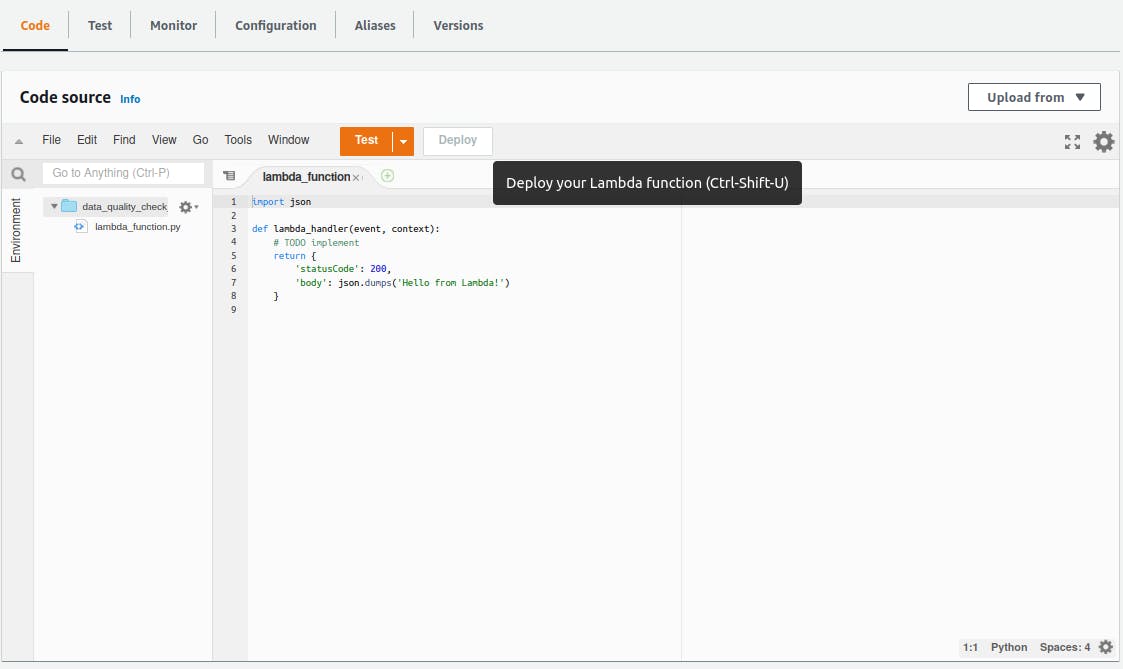
The lambda_function parameters event and context are just Python dictionaries. In our example, we will use just the event parameter, because it has all information we need to handle the CSV files.
Update Lambda function code
Open Lambda function editor and replace the hello-world example with the following code:
import csv
import boto3
s3 = boto3.client('s3')
def read_csv(body):
data = body.read().decode('utf-8').splitlines()
records = csv.reader(data)
content = []
for eachRecord in records:
content.append(eachRecord)
return content
def check_csv_header(content):
mandatory_headers = ['column1', 'column2', 'column3', 'column4']
headers = content[0]
if mandatory_headers == headers:
return True
else:
return False
def lambda_handler(event, context):
record = event['Records'][0]
user_id = record['userIdentity']['principalId']
csv_file_key = record['s3']['object']['key']
bucket_name = record['s3']['bucket']['name']
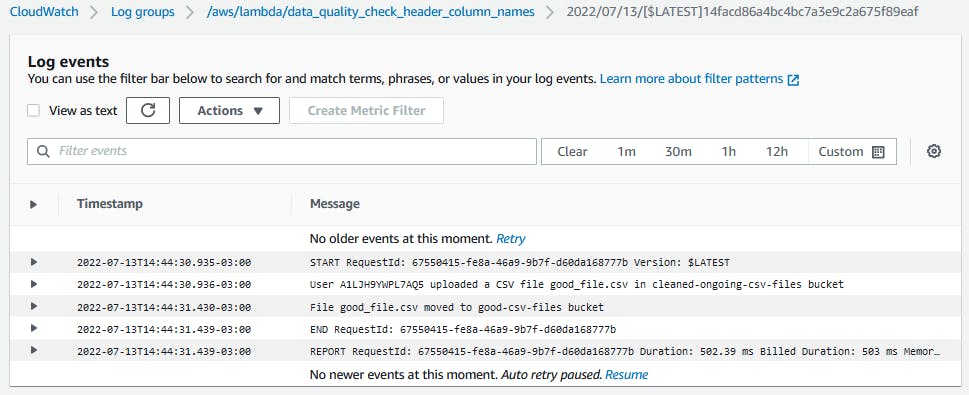
print(f'User {user_id} uploaded a CSV file {csv_file_key} in {bucket_name} bucket')
try:
response = s3.get_object(Bucket=bucket_name, Key=csv_file_key)
except Exception as e:
print(f'Error getting object {csv_file_key} from bucket {bucket_name}.')
raise e
body = response['Body']
content = read_csv(body)
if check_csv_header(content):
s3.upload_fileobj(body, 'good-csv-files', csv_file_key)
print(f'File {csv_file_key} moved to good-csv-files bucket')
else:
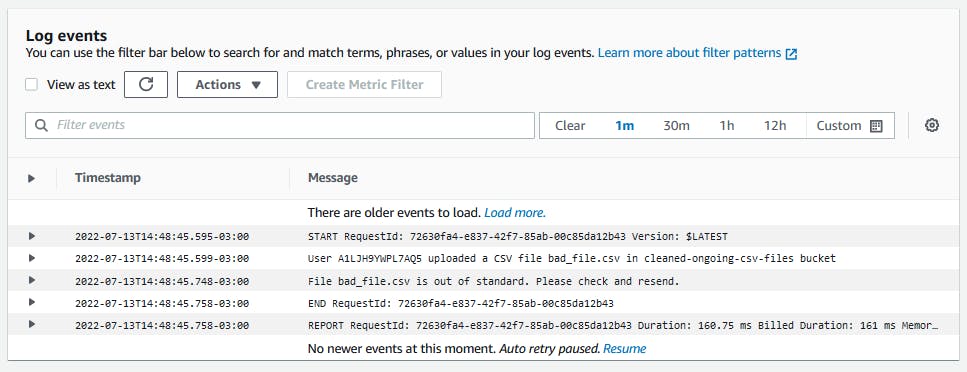
print(f'File {csv_file_key} is out of standard. Please check and resend.')
This code is too simple. The purpose is just to check if the first line of the CSV file is the header and contains the correct column names - check_csv_header function. Pay attention to the conditional statement in the end. If the check_csv_header returns True, the Lambda function moves the CSV file to another bucket - good-csv-files - we have created in a previous step. Otherwise, it does nothing and prints a message.
Add a trigger
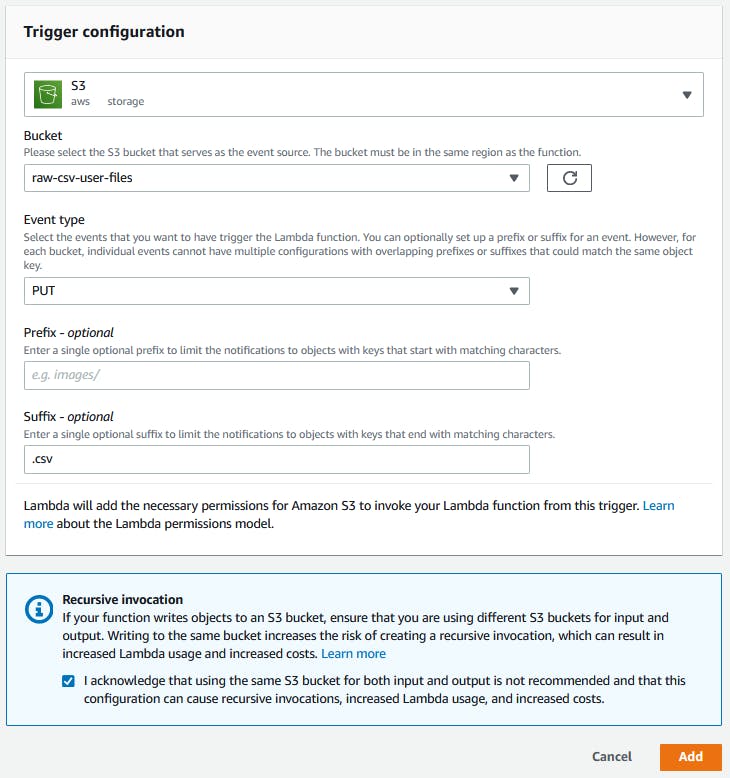
It's time to configure the type of event that will trigger your lambda function. In the function overview, click on Add trigger. In trigger configuration, you will see a lot of options. Follow the options:
- Choose S3 to select where the event comes from.
- In Bucket, select the bucket where users put the CSV files. Isn't the bucket you have created in a previous step.
- Event type corresponds to which type of event will trigger the function. In this case, you need select PUT. Every time a new object is uploaded (PUT) to this bucket, the trigger is launched.
- As the bucket are flat structures, we organize them by the path. If you have a prefix to limit the files. You can pass it here. It's not the case.
- Use Suffix to limit the type of files that will be processed. In this case, complete with .csv.
- Mark the checkbox in Recursive invocation.
- Click in Add.
Testing your Lambda function
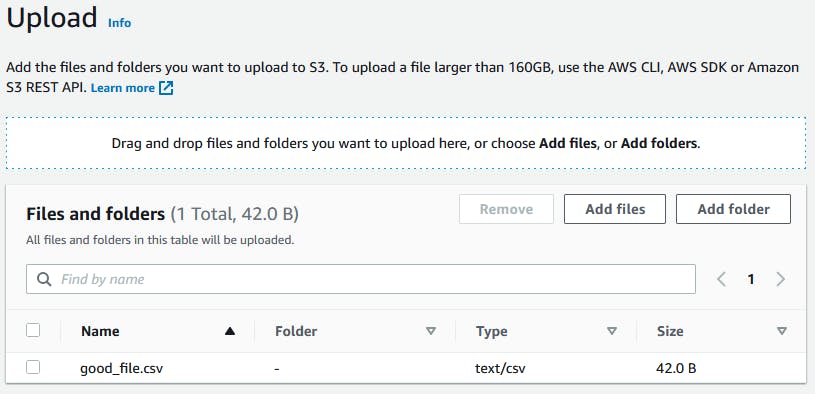
As you can see in the check_csv_header function, we just check if the CSV file has 4 columns. So let's test your Lambda function with 2 files - a good and a bad file. The bad file misses the last column. We just need to put a CSV file in the first bucket. Open the S3 console, select the bucket, click in Upload, select a CSV file and save.
In the Lambda console, select the Monitor tab in Function overview. Click in View logs in CloudWatch.

You will be redirected to the AWS CloudWatch service. Here, all the logs of your Lambda functions will be saved. In the Log stream list, select the last execution of your function. You will see the log messages.
Repeat the process to the bad file and you will see a different message.
Conclusion
AWS Lambda can be a very useful tool for data engineers. Even though we have a lot of options to do data quality checks, AWS Lambda provides us with an easy way to eliminate bad data before it reaches your data pipeline.
AWS provides a free tier of services where AWS Lambda is placed in. The first one million requests per month are free. According to your usage, maybe you don't need to pay for that at the first moment.
In this article, we were focused on AWS cloud provider, but if your data pipeline is hosted in Google Cloud Platform, you can use the same principle with Google Storage, Cloud Composer, Cloud Functions, etc. Even Azure has similar services.